
Starting from a given dataset, training a Machine Learning model implies the computation of a set of model parameters that minimizes/maximizes a given metric or optimization function. The optimum point is generally found using a gradient descent-based method.
However, most models are defined with an extra layer of parameters, called hyper-parameters. Their value affects the parameters computed during model training and they cannot be estimated directly from the data. Examples are the regularization parameter for ridge regression models, the number of trees for random forest models, the number of layers in a neural network and many others.
The recommended method for hyper-parameters tuning depends on the type of model you are training and the number of hyper-parameters you consider. I will be focusing here on Grid Search, a simple hyper-parameter tuning method and one of the first to be thought to data science students. It requires the definition of a list of potential values for each parameters, training the model for each combination and selecting the values that produce the best results according to a given criteria.
Although the principle is straightforward, this method is still error-prone. Here is a list of the most common mistakes I have encountered.
1. Not checking the sensitivity with respect to the chosen grid
This error I’ve seen it happen quite a few times. Students define a grid on a parameter, run GridSearchCV, extract the hyper-parameter value corresponding to the best score, and …. that’s it!
No further analysis, no plots investigating what’s happening around this best value. Depending on how well the grid was defined, just looking at the best score and its corresponding hyper-parameter value might not be enough to draw the right conclusions. Which brings me to the next point.
2. Choosing an unfit range of values
When defining the values that compose the grid it is best to first choose a coarse grain grid over a large range of values in order to be able to identify the interesting areas for fine tuning.
Depending on how the grid is defined you might end up either thinking that the model is very sensitive with respect to the parameter variation :

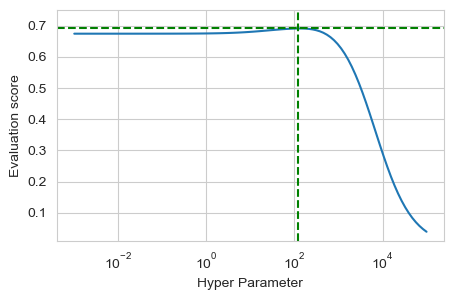
or that the model is not sensitive at all with respect to the chosen parameter :
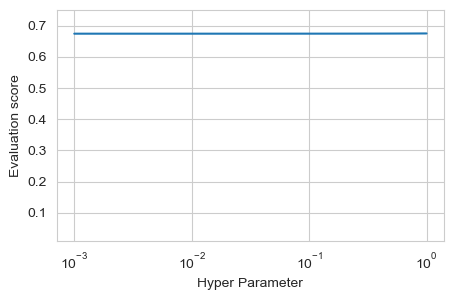
The truth might be somewhere in the middle so choosing a large enough range for the first test is important.
A fine tuning step can be done after that the overall sensitivity range has been identified in order to find the best value.
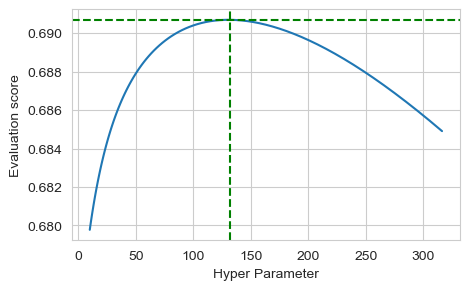
3. Not paying attention to the metrics
This next point is a little bit more philosophical but I think is important to keep in mind. The best value for the hyper parameters depends on the evaluation score that it is used.
In the first example I used the R2 score for the Ridge Regression. The sklearn package comes with a wide range of predefined measures of model performance to be used for the scoring parameter. Using the ‘max_error’ score in the previous example leads to a different optimal value for the hyper-parameter:
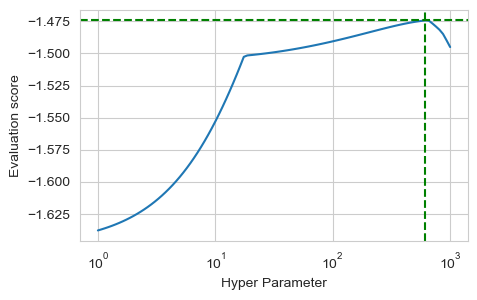
The score to be used for hyper parameters tuning needs to be chosen depending on the purpose of the model. It should be defined according to the business logic or the overall problem that we are trying to solve using the model. And GridSearchCV is flexible enough to allow us to define any type of custom function for evaluating the model score.
Let us consider a classification problem for which we want to train a logistic regression model. We want to tune the regularization parameter based on a custom score defined using expert domain knowledge.
Let us assume that in our custom score the false positives are 10 times more penalizing than the false negative. We can define a function that takes as arguments the known training output values and the values predicted by the model and compute the desired metric. We can the transform it into a score that can be used by GridSearchCV by calling the make_scorer function in the skearn metrics module.
Take away
Hyperparameter tuning requires a lot of attention in choosing the correct range of values for the grid and in analyzing the returned result. The quality of the obtained result also depends on the evaluation metric that is used and in many cases changing the evaluation metric will result in a change in the optimal hyper-parameter value.






